
The main aim of this blog is to correlate the Operating System Internals and the approach of Reverse Engineering a malware at code level. Here I will be showing what are the basic things that happen when a portable executable is started.
You can use any executable to deep dive into OS internals. Here I have used microsoft’s notepad.exe and to debug this I have used microsoft’s debugger called windbg, which can be downloaded from here.
Portable Executable
Portable Executable (PE) file format is organized as a linear stream of data. It begins with an MS-DOS header, a real-mode program stub and a PE file signature. Immediately after this is a PE file header and optional header. Beyond this, all section headers come followed by section bodies. In the end, few other regions of miscellaneous information, including relocation information, symbol table information etc are present.
PE format is a file format for executables, DLLs and others used in windows operating system. The PE format is a data structure that encapsulates the information necessary for the windows OS loader to manage the wrapped executable code. This includes dynamic library references for linking, API export and import tables etc.
Here we are going to understand PE structure, the concepts and various data directories inside it. Let’s get started.
At first, open windbg and set up the symbols to point to Microsoft’s Symbols Server. This is done to make our debugging easier. To understand more about symbols, you can read this microsoft’s documentation. Now open up the executable (notepad.exe in this case) in windbg. There are two ways in which we can open an executable in windbg:
- File -> Open Executable
- Launch the executable and then File -> Attach to a process…
Once opened, it shows all the loaded modules of notepad. We can also get the list of all loaded modules using lm command. Take a look at the following output:

We can see all the DLLs loaded with a range of addresses. This shows that each module occupies a specific range of address. For instance, notepad.exe uses some windows API functions exported by kernel32.dll, hence it is loaded along with notepad and the address range where it is loaded is 77de0000 77eb4000. From this we get the base address of kernel32.dll which is 77de0000. These base addresses of modules are very important as we will get to know that usually the value at hand is an RVA (Relative Value Address). This RVA has to be added in base address to get the original address.
DOS Header: Every PE begins with a DOS header having structure of type _IMAGE_DOS_HEADER. This occupies the first 64 bytes of the PE file. We can view this in windbg using image base address of PE image, 01000000:
dt _IMAGE_DOS_HEADER <base address of PE>

This gives us two important informations:
- e_magic - This has the MZ signature hex value 0x5a4d. Every portable executable will begin with this sequence. This field is used to identify an MS-DOS compatible file type.
- e_lfanew - This is a 4-byte offset to the PE file header. This value is in decimal and hence must be converted into hexadecimal before locating PE file header.
In this case, e_lfanew value is 224 which in hexadecimal is E0. Therefore, file header is present at an offset of E0 from the base address of the PE.
Real-Mode Stub Program: This is an actual program run by MS-DOS when the executable is loaded. For a MS-DOS executable, the application begins executing from here. For newer windows operating systems, a stub program is placed here that runs instead of actual application. This program just prints a line of text, such as “This program cannot be run in DOS mode”.
PE File Header
The PE file header structure is defined as:
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
The information in the PE file header is basically high-level information that is used by the system or applications to determine how to treat the file. The first field is used to indicate what type of machine the executable was built for. Likewise other entries have their own significance.
Now let us see the PE header of our executable. The syntax to see PE Header is:
dt _IMAGE_FILE_HEADER <image_base_address + e_lfnew>

Here machine field has value 0x14c, which shows that the type of target machine is intel 386 or later processors. see machine types. We can also see that the number of sections is 4. This indicats the size of section table is 4, which immediately follows the headers.
Another way to get the PE header of executable is:
!dh <image base address> <option>.
Here option can be:
-f Displays file headers.
-s Displays section headers.
-a Displays all header information.

PE Optional Header
The next few bytes (0xEO bytes) in the executable file make up the PE optional header. Though its name is “optional header,” rest assured that this is not an optional entry in PE executable files. The optional header contains most of the meaningful information about the executable image, such as initial stack size, program entry point location, preferred base address, operating system version, section alignment information, and so forth. The above image shows the optional header entries as well.
The IMAGE_OPTIONAL_HEADER structure represents the optional header as follows:
typedef struct _IMAGE_OPTIONAL_HEADER {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
Few important entries in this structure are:
AddressOfEntryPoint: This is the address of entry point relative to the image base when the image is loaded into memory. For program images, this is the starting address. For device drivers, this is the address of initialization function.
DllCharacteristics: Different characteristics that the linked libraries have. The value we have for notepad is 0x8140, which is the sum of 3 values, 0x8000(terminal server aware), 0x100 (NX compatible) and 0x40 (dynamic base, ASLR enabled). see DLL characteristics for more info.
Subsystem: The subsystem that is required to run this image.
Data Directories
The PE optional header gives many information including data directory arrays which is highlighted in the above diagram. The data directory indicates where to find other important components of executable information in the file. It’s an array of structures of IMAGE_DATA_DIRECTORY and here two fields are shown for each: Relative Virtual Address and size. This is an 8-byte field that has the structure:
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
Here we are not going to see all the sections that can be present in an image, but only the important ones for now.
Import Directory
The import section (usually .idata) contains information about all the functions imported by the executable from DLLs. This information is stored in several data structures. The most important of these are the Import Directory and the Import Address Table. The Windows loader is responsible for loading all of the DLLs that the application uses and mapping them into the process address space.
Import table contains an array of data structure of type _IMAGE_IMPORT_DESCRIPTOR. This structure has following form:
typedef struct _IMAGE_IMPORT_DESCRIPTOR{
_ANONYMOUS_UNION union{
DWORD characteristics;
DWORD OriginalFirstThunk;
} DummyName;
DWORD TimeDateStamp;
DWORD ForwardChain;
DWORD Name;
DWORD FirstThunk;
} IMAGE_IMPORT_DESCRIPTOR, *PIMAGE_IMPORT_DESCRIPTOR;
Two important fields at this point are, OriginalFirstThunk and FirstThunk. Each of these point to a table.
OriginalFirstThunk -> Imports Name Table
FirstThunk -> Import Address Table (IAT)
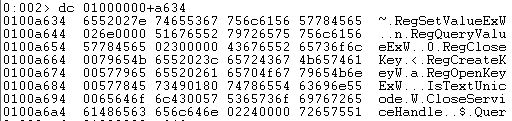
Let us start by viewing the memory at the Import Table Virtual Address which, from the PE Header, is present at 0xA048 (RVA) from the base address:

We can now relate this to the _IMAGE_IMPORT_DESCRIPTOR structure.
OriginalFirstThunk = 0000a234
ForwardChain = ffffffff
TimeDateStamp = ffffffff
Name = 0000a224
FirstThunk = 00001000
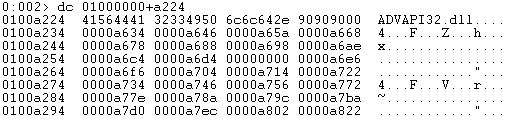
Let us now view the address pointed out by OriginalFirstThunk:

We get a list of RVAs which are also called _IMAGE_THUNK_DATA which in turn points to the structure of type _IMAGE_IMPORT_BY_NAME structure:
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
BYTE Name[1];
} IMAGE_IMPORT_BY_NAME,*PIMAGE_IMPORT_BY_NAME;
Here, Name[1] is the name of the imported function which can have a varibale length. So, this means that _IMAGE_THUNK_DATA and _IMAGE_IMPORT_BY_NAME structures have one to one correspondence.
We can view this as:
Now, let us talk about FirstThunk. FirstThunk is very similar to OriginalFirstThunk, i.e. it contains an RVA of an array of IMAGE_THUNK_DATA structures. In order to understand, suppose you have two arrays which are filled with RVAs of those _IMAGE_IMPORT_BY_NAME structures, so both arrays are exactly the same. Then assign the RVA of first array to FirstThunk and RVA of second array to OriginalFirstThunk.
But why do we need two exactly same arrays?
This is because when the PE file is loaded into memory, the PE loader will look at the IMAGE_THUNK_DATAs and IMAGE_IMPORT_BY_NAMEs and determine the addresses of the import functions. Then it replaces the IMAGE_THUNK_DATAs in the array pointed to by FirstThunk with the real addresses of the functions. Thus when the PE file is ready to run, these two arrays become very different. The Import Name Tables are left alone and never modified. The Import Address Tables are overwritten with the actual function addresses by the loader. The loader iterates through each pointer in the arrays and finds the address of the function that each structure refers to.
In this case, the FirstThunk table contains:

We see that it is already populated with virtual addresses. Let us view them:

So, these are virtual addresses of functions imported by PE.
We see this table already populated because our PE is already loaded by OS loader and the Import Address Table is already filled with function pointers as discussed earlier.
Now, let us look at the Name field in _IMAGE_IMPORT_DESCRIPTOR. This field gives us the information about the name of modules loaded.
The next module loaded is:
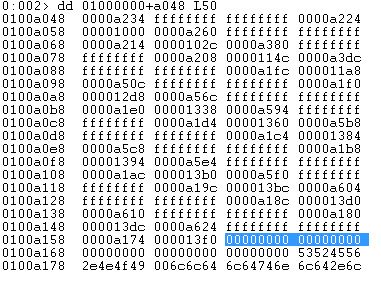
The end of the _IMAGE_IMPORT_DESCRIPTOR array is denoted by a structure filled with all NULL values as shown below:
Import Address Table (IAT)
IAT consists of mappings between the absolute virtual addresses and the function names which are exported from different loaded modules.
Let us see how we can grab this list of loaded modules.

here, L is used to denote the size and is divided by 4 to take steps of 4 bytes while displaying the addresses.
The question now is, how did IAT get filled up at run time? We will try to find out this.
Export Directory
This section is particularly relevant to DLLs. Each loaded module will have it’s own Export Directory. It is a structure called, IMAGE_EXPORT_DIRECTORY, having the following form:
Private type IMAGE_EXPORT_DIRECTORY {
Characteristics as Long
TimeDateStamp as Long
MajorVersion as Integer
MinorVersion as Integer
lpName as Long
Base as Long
NumberOfFunctions as Long
NumberOfNames as Long
lpAddressOfFunctions as Long
lpAddressOfNames as Long
lpAddressOfNameOrdinals as Long
}
End Type
A summary of the Structure: This contains pointers to 3 arrays. The pointers are in the form of RVAs relative to the base address of the image.
These arrays are:
AddressOfFunctions: It is an arrays of RVAs of the functions in the module.
AddressOfNames: Array of RVAs each corresponding to function name strings of exported functions.
AddressOfNameOrdinals: It gives an index or an offset into the AddressOfFunctions array to get the address of the function name.
So the flow is something like this: The function name is fetched using the Export name table and the corresponding entry in the Export Ordinals Table is looked up to get the index or offset. This index is used to parse the Export Address Table and fetch the function address.
Export Name Table > Export Ordinals Table > Export Address Table -> Function Address (VA)
This should now make it clear how the OS loader gets to know the addresses of functions which are imported by the main module.
Section Table (Section Headers)
Each row in a section table is a section header. This table is just after the optional header finishes. There is no direct pointer to this table in the file header, therefore this positioning, just after the optional header, is required. The number of entries in a section table is determined by the NumberOfSections field in the file header, which is 4 in our case. Each section header is of 40 bytes (0x28) and has the following format:
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
To determine the position of this section table, we have to add base address, offset of file header, size of file header and size of optional header. The base address of notepad is 0x01000000, 0xe4 (file header), 0x14 (file header size) and 0xe0 (optional header size). Then we can fire up the command dc <sum of these RVAs> to get the section table as follows:

As you can see, we indeed have 4 sections namely .text, .data, .rsrc and .reloc. To get the different values, as per the structure, of first section we can run the command dt _IMAGE_SECTION_HEADER <section table address>. To get the other sections, we can just keep adding the size of each section header, i.e., 0x28, as below.

One important field that section header has, is the Characteristics flag. This describes what all are the features of that section. For example, let us take .text sectoins characteristics value, which is 0x60000020. This value is actually a sum of 0x40000000(IMAGE_SCN_MEM_READ) + 0x20000000(IMAGE_SCN_MEM_EXECUTE) + 0x20(IMAGE_SCN_CNT_CODE). Which in short means that this section contains executable code which can be executed and memory read can happen on this region.
While on the other hand, if we check .data section’s characteristics (0xc0000040), one can deduce that this section contains initialized data (0x40), can be read(0x40000000) or written to(0x80000000). This means that this section is only for storing/manipulating data. But no execution will happen in this section. This means that .data section is NX(No eXecutable) protected. see section flags for more info.
That’s all for this blog!
References
Here are some links to understand more about PE file format:
useful links for winDbg: